
ASA Cluster
Introduction
Any serious network requires High Availability. Network architects look to remove single points of failure. Firewall’s are no exception to this rule. If an ASA fails, and there’s no high availability, one of two things may happen. One possibility results in blocked traffic, which results in outages. As an alternative, traffic may bypass the ASA, without security. Neither option is desirable.
The ASA supports two types of High Availability. The first is failover, which places ASA’s in a pair. Traffic flows through one or both ASA’s. If there is a failure of one ASA, traffic continues to flow through the second ASA. The pair may be in Active/Standby, where one ASA passes traffic and the other waits until it’s needed. Or, they may be in Active/Active mode, where each ASA takes about half of the load. Active/Active requires the use of contexts.
The second type of High Availability is Clustering, which is the focus of this article. Until recently, clusters were only supported on the 5585 ASA’s. More recently, smaller X-Series ASA’s models have added this feature.
ASA’s can use the traditional ASA image or the newer Firepower Threat Defence (FTD) image. Currently, only the Firepower 4100 and 9300 appliances support FTD Clusters. This article focuses on the traditional ASA image, version 9.6.
For cluster configuration, check out the ASA Cluster Configuration page.
Cluster Members
Roles
There are two roles an ASA can hold in a cluster. One member will be the primary unit. The rest of the members are secondary. Documentation before 9.6 refer to these roles as master and slave. Either terminology is fine.
The first member in the cluster will be the primary by default. Of course, this is only natural, as it’s the only cluster member. Elections become necessary when adding more units to the cluster. The priority influences the outcome of the election. The priority value ranges from 1 – 100, with 1 as the highest.
When a cluster boots up, or when clustering is enabled, it broadcasts an election request. If it doesn’t get a response, it will continue to broadcast every 3 seconds. Any unit with a higher priority should respond to the broadcast. If it does not get any response after 45 seconds, it will become the primary unit. If two members have the same priority value, the serial numbers break the tie.
There is no pre-emption in a cluster. A new unit with a higher priority will not become the primary automatically. The primary will only change if there is a failure, or if the primary is manually changed. This is to prevent disruption to centralised features. There will be more detail on this later.
If cluster enabled interfaces fail on a member, the member is removed from the cluster. Any connections owned by a failed member get moved to other members. A failed primary triggers an election. A failed member may try to rejoin the cluster automatically. But, this depends on the reason for which it was removed.
Performance
If you have a two-member cluster, you may expect to double your performance. This, unfortunately, is not true. As a rough idea, you can expect:
- 70% of the combined throughput of all members
- 60% of the maximum connections of all members
- 50% of the connections per second of all members
Cluster Control Link
The Cluster Control Link (CCL) is the ‘back-plane’ between the ASA member units. The CCL is different to and separate from the data interfaces. The CCL carries control messages between members, as well as data traffic. The CCL is a mandatory component of the cluster.
Control traffic includes elections, configuration replication, and health monitoring. Data traffic includes state replication, ownership queries, and forwarding data packets between members. All these types of traffic are covered in more detail through the article.
The CCL for each member has an IP address. All CCL IP addresses need to be on the same subnet. This should use a dedicated subnet and VLAN to isolate traffic from the rest of the network.
The CCL interfaces need to be dedicated. They can’t be a subinterface of another link. They must also connect via switches, not with cross-over cables between the ASA’s. This is true even when the cluster only contains two members. The reason for this is due to unit failure. Imagine if the ASA’s are directly connected and interfaces go down on one unit. In this case, the interfaces on the other unit will go down as well. When connected to a switch, the only unit removed from the cluster is the one with failed ports.
In ASA 9.6 and later, the CCL must have less than 20ms of latency, with no drops or out-of-order delivery of packets. Older versions are even more restrictive, and need less than 5ms of latency.
CCL Failure
The CCL is a critical component of the cluster. If the CCL interfaces fail on a member, the member disables its data interfaces. The member is then removed from the cluster. In most cases, the member unit will automatically try to rejoin the cluster when the CCL is repaired. Some older versions required manual intervention to rejoin the cluster. If the CCL fails when it initially joins the cluster, it will need manual intervention.
When the CCL fails, the management interface stays up. As shown later in the article, the management interface receives a unqiue IP address from a pool. If the unit is reloaded while the CCL is down, the unit will be unable to get another IP from the pool. For this reason, it is critical to have console access to the device.
HA/Cluster Support
Up until recently, only the 5585’s supported clustering, with up to 16 units per cluster. If more than 8 units need to be active, make sure to connect to a supported switch. The reason for this is many switches support only 8 active links per port-channel. The newer Nexus images support 16 active links per port-channel.
The cluster does not support all switches, so be sure to look at Cisco’s supported switches guide. They will also need to run an appropriate software version.
Other 5500 X-series ASA’s added support in version 9.1(4), but have a limitation of 2 nodes per cluster. Models lower than 5512-X do not support clustering. The 5512-X requires correct licenses to use clustering.
Each member unit needs to be the same model, and contain the same DRAM. They need the same IOS image (except while upgrading). They also need to be in the same context mode (single or multiple) and firewall mode (routed or transparent).
Traffic
Connections
Every packet is part of a connection. For connections, the ASA defines three roles; The Owner, the Director, and the Forwarder.
Every connection that passes through the cluster has a single Owner. All packets in a connection must pass through the owner. The owner is the unit which receives the first packet of the connection. In the case of TCP, this is the SYN packet in a three-way handshake. The owner maintains information on the connection. It and encodes its own information into the SYN packet before it forwarding it.
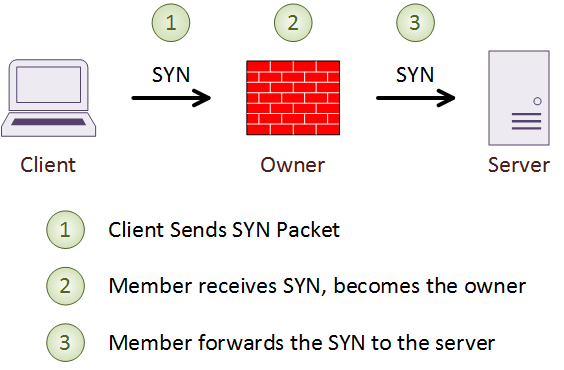
To guard against failure, each connection also has a single backup, called a Director. The owner chooses the director based on a hash of the IP addresses and ports of the connection. If the director fails, the connection owner chooses a new director.
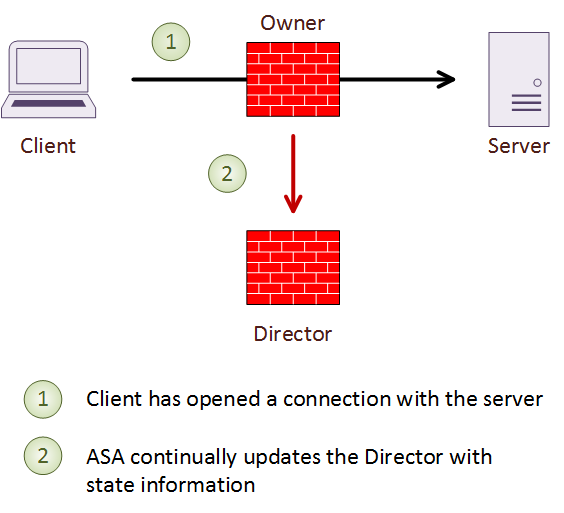
The director does not take over the connection if the owner fails. Instead, it maintains a a backup of the connection details, to quickly establish a new owner. If the owner fails, the first member to get a packet from the connection becomes the new owner. The new owner performs a lookup to the Director to get the connection details.
A forwarder is any unit which receives a packet from a connection it does not own. When this happens, the Forwarder finds the Director. To do this, it gets a hash based on the source and destination IP address and port numbers. It then looks up the director to get the connection owner, and forwards the packet over the CCL to the owner. This way, all packets from a connection pass through the owner. In the case of short-lived connections, such as ICMP and DNS, the packet is sent to the director. The director then forwards it to the owner.
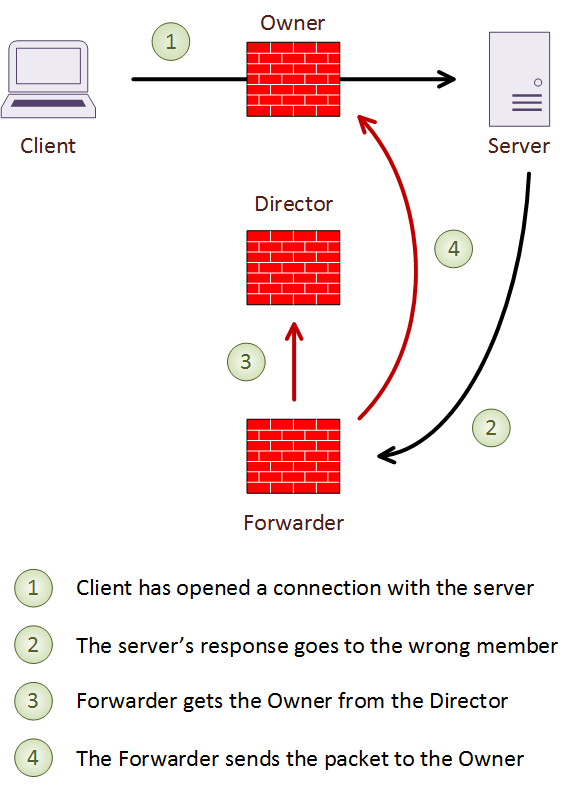
If a Forwarder receives a SYN/ACK packet, it can determine the owner by the contents of the TCP cookie. When using TCP sequence randomization, the TCP cookie gets modified. In this case, the ASA forwards the SYN/ACK packet to the Director to deal with.
If there are too many connections for a single ASA, it is possible to re-balance connections. While this is a supported option, it is not recommended by Cisco. The reason is because re-balancing adds more load to an already overloaded unit. If this is happening, connection re-balancing is not the answer. Instead, it is better to tweak load balancing on the connected switch, to deliver packets in a better way.
Load Balancing
Connected switches or routers deliver packets to the cluster. These need to use good load balancing methods. This is to consistently deliver packets to the same member.
There are four load balancing methods supported by the ASA:
- Spanned-Etherchannel – This is the recommended method. The ASA connects to a switch with a multi-chassis etherchannel, such as vPC or VSS. The switch treats all members in the cluster as a single appliance
- Policy Based Routing – The upstream/downstream routers use ACLs and route-maps to forward the packets. This supports Routed Mode only
- Equal Cost Multipath (ECMP) – Routers have several routes with equal costs to deliver packets. This supports Routed Mode only
- Intelligent Traffic Director – ITD is only supported in newer ASA images, and needs a Nexus switch. This is like PBR, but with advanced features like granular load distribution. If you use ITD, configure Bi-Directional Load Symmetry
NAT does not balance well, as it changes IP’s and port numbers in the packet. This means an ingress packet may be load balanced in a different way to an egress packet. If this happens, the result is traffic asymmetry.
You will need a pool of IP addresses for Port Overloading. There must be at least one IP per cluster member in the pool. Each IP in the pool is only assigned to one member at a time.
Interface Modes
There are two modes interfaces can be in; Spanned-Etherchannel or Individual. All data interfaces must be in one mode or the other. A combination of modes is not possible.
Use spanned-Etherchannel mode with a vPC or VSS enabled switch. Use individual interface mode with PBR, ECMP, or ITD for load balancing.
Spanned EtherChannel
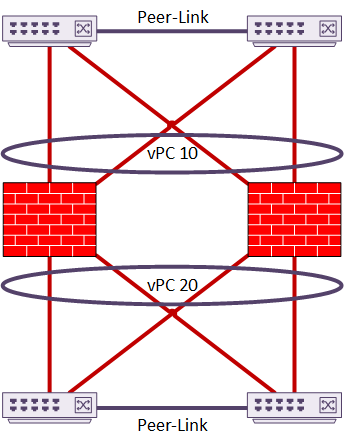
Spanned-Interface mode uses a Multi-Chassis Etherchannel such as vPC or VSS. This makes the upstream switch appear as a single switch. The ASA’s also appear to be a single unit to the switches. This is similar in concept to a back-to-back vPC topology. This is the recommended topology, as it has a very fast recovery time.
You could use a single switch instead of two, but this defeats the purpose of High Availability.
This example shows a two-member cluster connected by vPC. In this case, there is only a single set of interfaces. These interfaces are in a port-channel. This implements sub-interfaces based on VLAN. This is sometimes known as Firewall on a Stick.
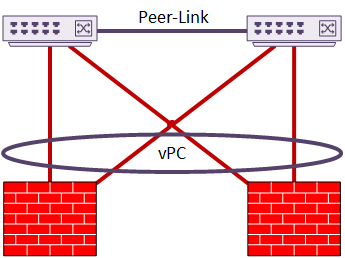
As another option, the cluster may have two or more vPC’s configured. The interfaces are members of different port-channels. This does not need sub-interfaces, although they are still an option if desired.
In this topology, channel 10 may be the Inside interface, and channel 20 may be the Outside.
There is little manual configuration required for load balancing, as LACP does it all. The ASA side uses a modified version, called cLACP.
The ASA uses a proprietary hashing algorithm, based on IP addresses and port numbers. Whenever possible, do not change this from the default setting.
If possible, avoid NAT. This can affect load balancing, as the IP addresses and port numbers can change from one side of the ASA to the other. This causes the switches to generate different hashes for the packets. This may result in asymmetric packet delivery. This means they don’t arrive on the same cluster member each time.
Cisco recommends vPC’s or VSS links. A Nexus switch with a recent image will support up to 16 active links in a port-channel. This all links in the spanned-etherchannel. Each ASA unit will support up to 8 active links and 8 standby links.
If it’s necessary to use a different LACP hash algorithm, use Symmetric Hashing. This means all packets for a connection should always arrive on the same cluster member. If there are inside and outside switches, they should use the same hashing method.
The best hashing methods use source and destination IP addresses, and port numbers. These are src-dst-ip and src-dst-ip-port. Using VLAN in hashing can have sub-optimal results. When using a switch chassis, use the same line card types all units.
Spanned-Etherchannel supports both routed and transparent modes. If using dynamic routing, only the primary (master) unit will form neighbour relationships. The routes are then replicated to each of the secondary (slave) units. Each unit makes its own routing decisions based on its own routing table. OSPF LSA’s are not replicated from primary to secondary.
IS-IS is not supported with spanned-etherchannel at all.
To start with, the primary handles all multicast routing and data packets. Eventually, the cluster establishes fast-path forwarding. After this, each unit can forward multicast data packets.
Individual Interface Mode
In individual interface mode, each interface has its own IP address. The primary has a pool of IP’s, and allocates one to each unit in the cluster. There is one more IP, which the primary uses as a secondary IP. This IP is for cluster management. If the primary fails, this IP moves to the new primary.
Individual interfaces support routed mode only.
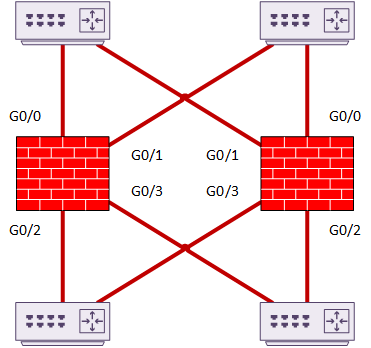
PBR, ECMP, or ITD provide packet load-balancing. One of these technologies will run on the connected routers. The cluster relies on routing protocol convergence to handle failures. Convergence may not be quick if the routing protocol is not tuned.
Each cluster member runs it’s own instance of the routing protocol. The routers ‘sandwiching’ the ASA’s see the cluster as many paths with equal costs.
Only the primary member handles multicast packets.
Management and Monitoring
Management
Management interfaces may also be set to spanned-etherchannel or individual mode. This does not have to match the mode of the data interfaces. The best approach is spanned-etherchannels for data, and individual mode for management. In this configuration, the management interface does not take part in dynamic routing. It requires a static route to be in place.
Individual interface mode is best, as it allows management connections to each member. The management IP addresses come from an IP pool, with an another IP allocated to the cluster as a whole. Outbound management connections, such as TFTP, Syslog, and so on, use the local IP address.
When using etherchannels for management interfaces, a single IP address is configured. The primary holds this IP address, and represents the entire cluster. As a result, you cannot connect connect to a secondary unit by IP. It’s important to have a console connection.
All management, monitoring, and configuration happens on the primary unit. The only exception is the initial cluster configuration (called the Bootstrap Configuration).
The primary queries and reports on all runtime statistics, resource usage, and so on. It does this on behalf of all secondary units. Secondary console messages can be replicated from any secondary unit to the primary. Direct monitoring and file management of secondaries is possible. For this, they need their own IP addresses.
The primary generates any RSA keys, and replicates them to each secondary.
Health Monitoring
Health monitoring of each member is needed to detect failures. The primary monitors each secondary, via the CCL link. In turn, each secondary monitors the primary, also over the CCL. The monitoring period is configurable.
Each unit also monitors its own interfaces. The members notify the primary of any changes. Interfaces are only monitored if they’re configured with the nameif command.
When a unit joins a cluster, there’s a grace period when the interfaces can flap without penalty. Spanned-etherchannels, for instance, can flap for up to 90 seconds without repercussions.
Feature Support
Clusters do not support all features, and some features behave differently. Before designing the cluster, be sure to check the Cisco documentation for the version youwish to use.
Unsupported Features
- Remote Access VPN
- VPN Load Balancing
- Some application inspections
- Botnet Traffic Filter
- Auto Update Server
- DHCP (other than relay)
- Failover
Centralized Features
The primary member handles centralised features. They are not scaled to other units. If a secondary receives a centralised connection, it sends the packets to the primary.
Traffic re-balancing may also interfere with the efficiency of centralised features. If a centralised connection moves to a secondary, it will forward the packets back to the primary.
When the primary fails, it drops all centralised connections. These are re-established again on the new primary.
Centralised features are:
- Site-to-site VPN
- Some application inspections
- Dynamic routing in spanned etherchannel mode
- multicast routing in individual interface mode
- static route monitoring
- IGMP and PIM multicast control plane processing. Data plane functions are decentralised
- Authentication and Authorization for network access. Accounting is decentralised
- Filtering services
Here is a general way to think about it. Control plane features are centralised, which the primary member handles. Data plane functions are decentralised.
Individual Features
Some features work on each member unit. The cluster may replicate data across the members, but each ASA does it’s own processing. These features are:
- QoS – Conform and burst rate use values for the local member
- Threat detection – Port scanning detection does not work. The connection load balancing distributes the scan across the cluster
- Resource management – Enforced on each unit based on local resource usage
Also, some control plane functions are also per unit:
- Syslog – Each unit generates its own messages. Syslog can use unique device ID’s or cluster wide ID’s
- NetFlow – Each member generates its own flow
- SNMP Polling – Uses the local address of each member
NAT
NAT breaks traffic symmetry, as the translation changes IP addresses and port numbers. This may result in delivery to the wrong members, and the CCL getting extra load.
When using individual interfaces, Proxy ARP is not sent for mapped addresses. Interface PAT is also not supported for individual interfaces.
With port overloading, the primary allocates IPs from a pool to each member in the cluster. The allocation is as even as possible. If a member gets a connection, and there’s no IP address available, the connection is dropped. This will happen even if other members have resources available. A case where this may happen is if there is not enough IP’s in the pool. For example, a four member cluster requires at least four IP’s in the pool.
Round-robin for port-address translation (PAT) is not available.
The primary manages dynamic xlates. The primary replicates the translation table to all slaves. If a secondary receives a connection, and it doesn’t have an xlate, it will request one from the primary. The secondary is still the owner of the connection.
Firepower
Firepower is outside the scope of this article. But it is still important to touch on it briefly.
When clustering ASA with Firepower Services, only the ASA features are clustered. The firepower modules do not have their state or configuration replicated.
Inter-Site Clustering
Inter-site clustering is a relatively new feature. It allows a single cluster to be stretched across more than one data centre. At this time, this is only supported on the 5585’s.
The DCI (Data Centre Interconnect) needs to be extremely reliable, and low latency. In fact, the latency needs to be less than 20ms. In addition, it needs to have enough bandwidth available; It can carry other traffic, but enough bandwidth should be reserved for clustering.
To work out the bandwidth requirements, first decide on an appropriate CCL size per member. The bandwidth required is half the number of members per site , multiplied by the CCL size per member. If the number of members per site varies, use the larger value in the calculation.
Connection rebalancing should be disabled when inter-site clustering is used. This is to avoid rebalancing connections to the wrong site. If this happens, traffic in site-A may be sent to site-B, then passed back to site-A. This would impact the DCI links, the CCL’s, and degrade performance.
The cluster uses an ID for each site. Each member is configured with the ID of the site it belongs to. Site specific MAC’s and IP’s are used, along with cluster global MAC’s and IP’s. Packets from the cluster use the site specific addresses. Packets to the cluster use the global addresses. This prevents switches from learning MAC addresses from different sites on different ports. A single MAC can only exist on a single port, so if it were learned from multiple locations, it would cause MAC flapping.
When virtual machines are moved from one site to another, LISP is used to notify routers of the move. While not running LISP themselves, the ASA’s can inspect this traffic to learn about location changes. The ASA’s can then move the connections to a member in the correct site.
Data VLANs need to exist in both sites. They can be extended with a technology such as OTV or VxLAN.
Migrated Comment:
VPNs
srt 2017-03-10 03:27
I understand that VPNs aren’t load balanced across the cluster somehow. However, site-to-site VPNs are a centralized feature. So to that end, lets say I configure 50 site-to-site VPNs that have an end point of this cluster on the director, how is that traffic handled? If I am running a spanned ether channel in front of this cluster is that how the SA is spread and the first cluster member to own the flow now holds the SA to the far end point?
Thanks
Migrated Comment:
VPN’s
li_hmlRLk1rjz 2017-03-10 06:24
The VPN’s will have their endpoint on the primary ASA. This is because they are a centralised feature.
When the first packet comes in, the member that receives it will forward it to the primary ASA. The primary ASA then becomes the owner for that connection.
As the owner, it will then select a different member to become the director. The director maintains a backup of the connection details, in case the primary ASA fails.
For any traffic that is non-centralised, the member that gets the first packet becomes the owner. This is decided by the hashing algorithm on the switches that the cluster connects. So if you have spanned-etherchannel connecting with vPC to a Nexus pair, the hashing algorithm (likely src-dst-ip-l4port) will decide which vPC link to send the packet out of. The packet will then arrive at a particular ASA, which becomes the owner.
Does that help?
Migrated Comment:
VPN’s
SRT 2017-03-11 01:27
Yes, it does. I just needed clarification that a centralized feature = the Primary ASA handles this traffic.
Thanks!
Migrated Comment:
VPN’s
li_hmlRLk1rjz 2017-03-11 14:58
I attended a Cisco Live session yesterday on ASA clustering, run by Andrew Ossipov.
In short, they are decentralising site-to-site VPN.
This will be available in either 9.8.1 (released by the end of April) or 9.8.2 (September I think?)