
HTTP Protocol
Overview
HTTP, or Hypertext Transfer Protocol, has been the backbone of the web since 1990. It’s easy for us as networkers to dismiss this protocol as only for web developers.
Of course, it’s not that simple. As networkers, we need to capture HTTP traffic to analyse in Wireshark. Also, it’s becoming more important for us to consider network programmability. This includes REST API’s.
This article endeavours to provide an overview of the HTTP protocol. This is suitable to learn the basics.
HTTP is a generic protocol. It transfers information, but it is not concerned with what that information is. This makes it useful for several different purposes.
The most common use is for a web browser to retrieve web pages from a web server. In this case, HTTP will transfer an HTML file from a server to a client, and the client will render it on the screen. It may also transfer other files, such as Java Script.
HTTP is also stateless and connectionless. This means that the client and server do not need to track the state of every connection in progress. A client may open a connection, submit a request, and immediately close the connection.
There are three versions of HTTP. These are version 1.0, released in 1990, version 1.1 from 1997, and version 2.0 from 2015. Version 1.1 is still the most common today, but there are some applications, such as wget, that still use version 1.0.
Version 1.1 allows several transactions over a single connection by default. This is still considered to be connectionless. HTTP allows dropping the connection at any time. A new connection may continue the transaction.
Clients and Servers
HTTP uses a client and server framework. The whole point of HTTP is to define how a client will form a request, and how a server will respond.
In the diagram below, a web browser is a client. The client makes a request to the web server.
In the background, the server may perform extra functions, like looking up a database. Any back-end functions like this are transparent to the client. When the server is ready, it will create a response and send it.
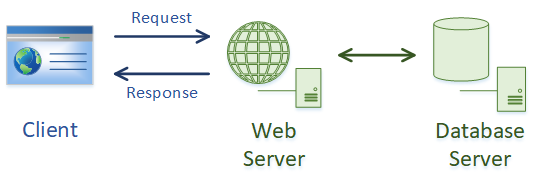
In this example, the server and the page that is being requested is the resource. We access the resource with a Uniform Resource Identifier or URI.
An example URI is http://networkdirection.net/homepage. This is often also known as a URL. While there may be some technical differences, here we use the terms interchangeably.
The URI contains:
- The protocol to use. In this case, http://
- The server to access (networkdirection.net)
- A port number. If none is listed, port 80 will be assumed for HTTP traffic (and port 443 for HTTPS)
- A path to the web page (/homepage here). If a path is not given, ‘/’ is assumed
HTTP Messages
Messages are passed between clients and servers. Clients make requests, and servers send responses.
In a client request, it will send a resource (URI), and an action for that resource. The server will send back a response code and any additional information.
Both requests and responses follow the same format. They contain four parts:
- A Start-Line
- Headers
- An empty line, which contains only ‘CRLF’
- An optional message body
The example below is a client sending a request to the server, and the server responding to the request.
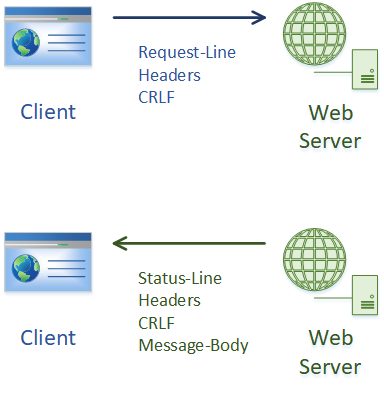
Start-Line
The start-line is either a Request-Line or a Status-Line. This depends on whether the message is a request or a response.
A Request-Line includes:
- A Method – These are the actions that are sent to the server
- A Request-URI – The resource to connect to
- Version – The HTTP version to use. This is either 1.0 or 1.1
A Status-Line includes:
- Version – 1.0 or 1.1
- Status Code – Indicates the response type
- Phrase – A short description of the code
Methods
Methods are the commands or actions that a client sends to a server. Version 1.1 defines 8 standard methods:
- GET – Retrieves information from the server. This does not alter the data that it retrieves
- HEAD – This is like GET, but the server will only return the Status-Line and headers. The message body is not returned
- POST – Sends data to the server. Often used when you fill in a form on a web page
- PUT – Also sends data, but more commonly used for uploading files
- DELETE – Remove a file from the server
- CONNECT – Creates a tunnel between the client and server. Often used to allow encryption (HTTPS) through an unencrypted HTTP proxy
- OPTIONS – Used by the client to see what options and methods the server supports
- TRACE – Used for debugging during development. Echo’s the input back to the client in the message body
Headers
Headers provide more information about the request, response, or message body.
A variable number of headers are in both requests and responses. Headers are technically optional, as there can be zero headers.
After all the headers, there is an empty line. This marks the end of the list of headers.
There are four types of headers:
- General – Apply to requests and responses
- Request – Only used in requests. Sends additional information about the client to the server
- Response – Only used in responses from the server
- Entity – Used with the message body
Message Body
Some requests and responses include a message body. This is a payload of data.
For example, in a request, the message body may include an XML file that the client is sending to the server. In a response, the message body may include an HTML file for the client web browser.
The Content-Length and Content-Type headers describe the content in the message body.
Status Codes
Server responses include a Status Code. These are a three digit code which indicates the response type.
No doubt you have seen a web page respond with ‘404 – page not found’. The ‘404’ value is the status code when a resource is not found.
Along with the status code is a Phrase. This is a short description of the status code. For example, code 404 includes the phrase ‘Not Found’.
The first digit of the status code indicates the type of code. There are five categories:
- 1xx – Informational
- 2xx – Success
- 3xx – Redirection
- 4xx – Client error
- 5xx – Server error
An HTML Example
The following example is a real HTTP request and response captured by Wireshark.
The traffic was generated by using Chrome to browse to http://192.168.40.128. The server is running a very simple Apache website, with PHP generating the HTML file.
In the Wireshark output, you will see rn shown regularly. This is the same as CRLF or End-of-Line.
Request
This image shows a request being made from the client to the server.
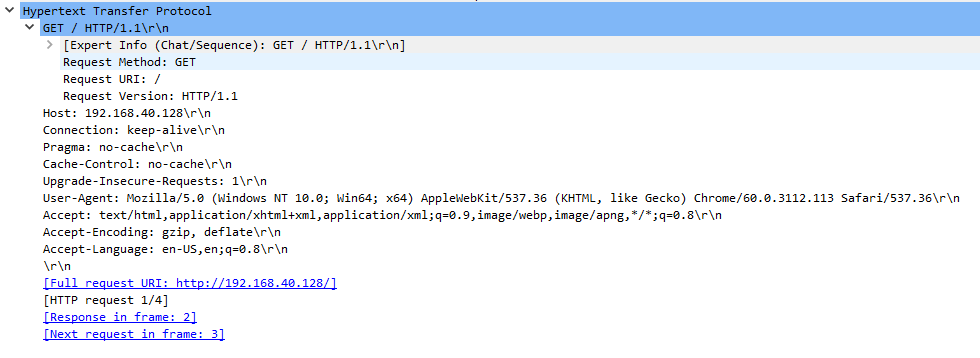
The request line, GET / HTTP/1.1 shows the following information:
- The method is GET, indicating that the client wants to retrieve something from the server
- The URI is ‘/’, showing that we want the resource at the root of the path
- The HTTP version on the client is 1.1
Next come the headers. Tthe server name, 192.168.410.128, is included in the Host header.
There are several additional headers used in this request:
- Connection – This tells the server whether the connection should be left open. Options are keep-alive and close.
- Pragma – A general header. No-cache is from version 1.0, and is maintained in version 1.1 for backward compatibility
- Cache-Control – A general header with rules that all caching systems must obey. In this case, no caching is allowed
- Upgrade-Insecure-Requests – As this is set to ‘1’, the client is telling the server that it prefers the content to be delivered over HTTPS if available
- User-Agent – Includes information about the client. Here, we are running Chrome on Windows 10
- Accept – Specifies the file types that the client will allow, such as HTML files
- Accept-Encoding – Specifies what encoding types the client will accept. GZIP is accepted here, which is used for compression
- Accept-Language – Any language that the client will accept. In this case, English and US English
After the headers is an empty line. This means that we’ve reached the end of the header list.
There is no message body in this example. The data shown after the empty line is diagnostic information provided by Wireshark.
Response
Here is the server’s response to the previous request.
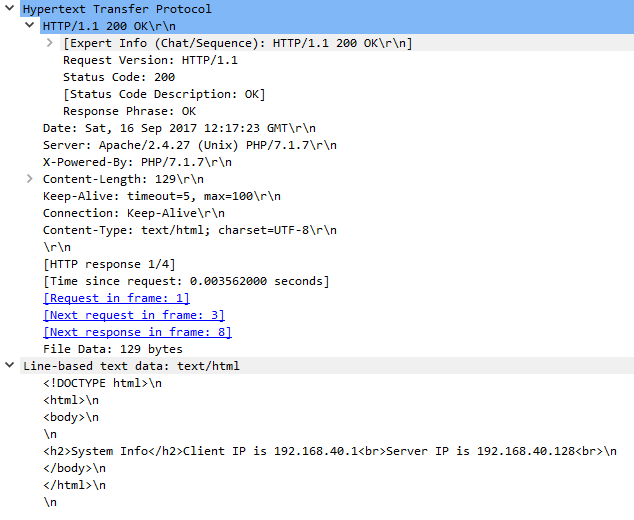
In the status-line, HTTP/1.1 200 OK, we can see three things:
- The HTTP version the server supports is 1.1
- The response code is 200. This is the code used for a successful transaction
- The description for code 200 is OK
The headers used in the response are:
- Date – The response timestamp. This is always in GMT
- Server – Contains information about the responding server. Here, the server is running Apache and PHP
- X-Powered-By – A non-standard header. In this case, PHP uses the header to send its version number to the client. Most headers beginning with ‘X-‘ are non-standard
- Content-Length – The length of the message body
- Keep-Alive – A non-standard header. The server is giving hints about the timeout and the maximum number of requests for this connection. The client does not have to use this information
- Connection – Set to Keep-Alive, so the connection doesn’t close after the transaction is complete
- Content-Type – Describes the type of data in the message body. In this case, the message body is an HTML file
After the empty line is the message body. As you can see, it is an HTML file.
Thank you ! 😀