
BGP in the Enterprise
There are a few ways that you may run BGP in the enterprise. Probably the most obvious is peering with your internet provider. One that you may not have considered is running BGP as your IGP.
But why would you want to do this? There may be a few reasons. Consider a case where you have several ‘islands’ of networks. Perhaps each network is administered by a different team, or they all run different IGPs. BGP can help with interconnecting these islands.
Sometimes there may be strict policy requirements. BGP is very helpful here. Communities are perfect for routing policies.
There are several upsides to using the BGP protocol:
- Like OSPF and IS-IS, it is supported by almost every vendor
- It can easily be used to connect to partner networks
- The AS is a well-defined boundary of trust
- Added efficiency with reduced flooding and anycast-routing
- Like EIGRP, it supports unequal-cost load balancing
- Supports traffic engineering on a per-hop basis
Of course, there are always downsides to consider:
- By default, BGP has slow convergence. Convergence can be tuned, but this requires more effort
- Lower-end routers may not support BGP or may require additional licensing
- Link bandwidth is not considered by default. Extra tuning is required to work around this
- By default, a full-mesh of BGP routers is required. We’ll discuss how to deal with this later
Design Overview
At a high level, there are six steps that you need to consider when designing iBGP.
1. Routing Goals
BGP often offers several ways to achieve a goal. Before starting a design, begin by working out what all your goals are. From there, work out the easiest solution to understand, implement, and maintain.
2. Autonomous System Numbers
Choose your ASN’s. Decide whether you will use private ASN’s or not, and make sure that they’re unique.
3. Sessions
Which of your sessions will be iBGP and which will be eBGP? Will you use route reflectors, and where will they be?
We will cover route reflectors in more detail soon.
4. IP Space
Design the IP space that you will use. Multi-homing, and whether eBGP will be part of the design will influence your IP space.
If your design does need to include eBGP peering, you need to decide on PA or PI addresses. If you connect to only one provider, Provider-Assigned addresses are ok. If you multi-home to two providers, you will need Provider-Independent addresses.
5. Routing Policies
Decide how to influence path selection. ASPath and Local Preference are often used here. Consider policies for inbound and outbound routes.
6. Communities
Communities apply routing policies across Autonomous Systems. Decide on the scheme you want to use to tag your routes with communities.
System Resources
Conserving Memory
Memory is a tricky thing in BGP. It’s notoriously difficult to scope the amount you’ll need. The reason is that memory usage is dependant on several different factors.
Each prefix will consume some memory. The more prefixes, the more memory consumed. Each prefix may have one or more paths. More paths mean more memory per prefix. Prefixes may also have a variable number of communities and attributes. Once again, the more communities and attributes, the more memory consumed per prefix.
To conserve memory, see if you can decrease the number of prefixes in the database. One way to do this is by creating aggregates (or summaries). Another option is to use filtering, which results in a partial routing table.
The number of neighbours influences the number of paths per prefix. Decrease the number of paths by decreasing the number of direct peers. To do this, consider route-reflectors or confederations to avoid creating a full-mesh.
You can filter out extended communities. Be careful with this though, as you probably need them. Also, try to limit the attributes applied to prefixes. For example, do you really need to apply path prepending as well as MED, or will just one attribute be fine?
Soft Reconfiguration and Route Refresh
The way you handle incoming routes will also affect memory and bandwidth resources. The two main features used here are Soft Reconfiguration and Route Refresh.
When peering with a neighbour, the neighbour transfers reachability information (prefixes). The local router applies policies, likely discarding some prefixes. After this, peers only send prefix change information. New policies aren’t applied until there’s a prefix update from the peer.
So how can we get the new policy to apply? One option is Route Refresh. This is a feature that both routers need to support. We can use route refresh to request prefix information from the neighbour again.
The second option is Soft Reconfiguration. When all the prefixes are first received from the peer, the prefixes are stored in an extra table. When changing the policies, the router can look at the original prefixes in the table.
So, which one is better? Route Refresh uses additional bandwidth when requesting routes. Soft Reconfiguration uses extra memory to store the routes. Both have their pros and cons.
As a general rule, stick with Route Refresh. Generally, memory savings are more important than occasional bandwidth savings.
Scaling iBGP
iBGP uses split-horizon to prevent routing loops. Any prefix learned from an iBGP router is not advertised to any other iBGP router.
The default way to deal with this rule is for iBGP to be fully meshed. But, this causes some scalability issues. To deal with these issues, Route Reflectors and Confederations are available.
Full Mesh
As we’ve already discussed, BGP requires a full mesh topology. To be clear, this is a full mesh of BGP TCP connections. This doesn’t mean that you need to connect each router physically.
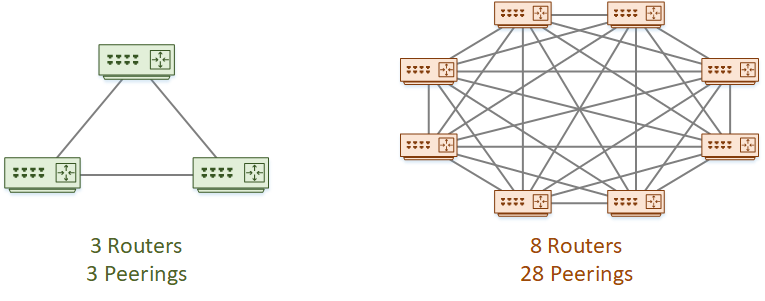
Even so, this is still a scalability problem. Each router has n – 1 peers. The total peerings in the network is n * (n – 1) / 2. As you can see below, this is fine for a small network of three routers. When the network grows, we have problems.
A full-mesh BGP topology places a burden on administration, CPU, memory, and bandwidth.
Route Reflectors
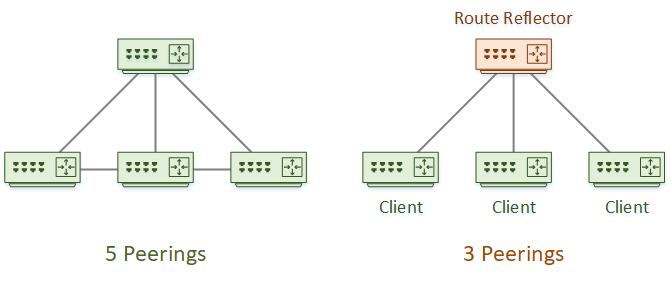
Route-reflectors change the way iBGP does its loop prevention. This relaxes the need for a full-mesh topology.
Certain BGP routers can be route reflectors. They become BGP ‘hubs’, that can readvertise routes to other iBGP peers.
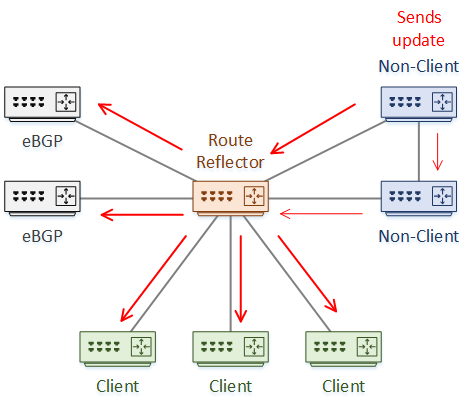
Any normal BGP router that peers with a Route Reflector is a ‘client’. There is no need for normal BGP routers to connect to a Route Reflector. If they don’t, they are ‘non-clients’, and the full-mesh rules still apply.
Update handling is different, depending on where they come from. The scenarios below will walk through this process. There is no route filtering or policies applied in these examples.
If an RR receives an update from an eBGP peer, the RR sends the update to other eBGP peers, to clients, and to non-clients.
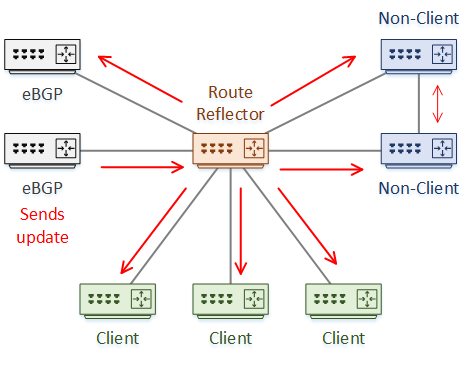
When receiving a route from an RR-client, it is forwarded to eBGP peers, clients, and non-clients. The original sender also gets the update, which it discards.
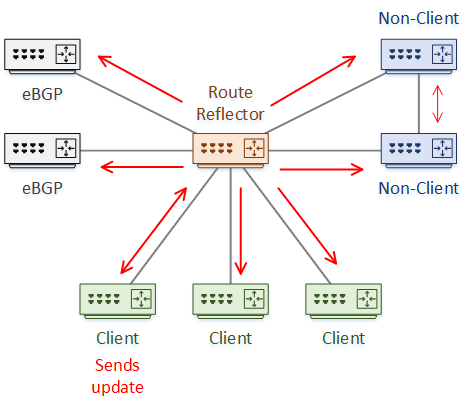
When receiving a route from a non-client, it is forwarded to eBGP peers and all clients. The split-horizon rule prevents the RR from sending the update to any non-clients.
Confederations
A Confederation is a method of dividing a large AS into smaller parts. Each of these parts is a sub-AS. From the outside, the network still looks like one large Autonomous System.
Each sub-AS peers with other sub-AS’s using eBGP. This reduces the iBGP connections and limits the need for iBGP full meshing. Within the sub-AS, the full-mesh requirement still applies. There may also be Route Reflectors in the sub-AS to further reduce the mesh.
Very large networks will benefit from confederations. They are also useful when there are mergers, or when business units need to manage their own areas.